
Most of the code I write at work is in the Dart programming language. Specifically, I’ve worked on some internal tooling that involved the static analysis libraries that ship alongside the language SDK. So when a colleague mused that he would like to be able to automatically generate UML diagrams for some of our libraries, I jumped on it. The result was the DCDG package and tool.
The first step is to install it:
$ pub global activate dcdg
Run it like this:
$ dcdg --help
You may need to add Dart’s package directory to your path before this will work, otherwise you can use pub global run dcdg instead.
To use the tool, navigate to a Dart on your file system and run the tool. By default, this will print the PlantUML markup for a pretty standard UML diagram for the package in question. You can either redirect this output to a file (dcdg > output.puml) or use the -o option to specify an output file (dcdg -o output.puml).
To turn the markup into a PNG image, just run the plantuml command on the file you created with DCDG (plantuml output.puml), this will create a file called output.png. You can also redirect the DCDG output directly into PlantUML by using the -p option, in which case the PNG image will be written to stdout, so you’ll need to redirect it to a file yourself:
$ dcdg | plantuml -p > output.png
There are a plethora of options (perhaps too many, actually). Let’s take a look at a few of them. First, it can be helpful to see just the public API for a package represented as a UML diagram, particularly if the diagram is to be included in public documentation. This is easily accomplished with the --exported-only flag:
$ dcdg --exported-only | plantuml -p > output.png
This will produce the image shown below when run on the DCDG codebase itself. DCDG doesn’t export very many classes since it is primarily intended to be used as a command line tool.

dcdg --exported-only | plantuml -p > output.pngAlternatively, someone might want to see a diagram with more detail, particularly if they plan to contribute to the code. However, we may want to exclude certain features, such as private class members, from the diagram to reduce clutter.
$ dcdg --exclude-private=field,method | plantuml -p > output.png

dcdg --exclude-private field,method | plantuml -p > output.pngIt is also possible to pare the diagram down to include only classes that inherit behavior from a particular class. This is done using the --is-a option (which can be provided more than once). The example below includes only the inheritance tree rooted at the abstract DiagramBuilder class from DCDG.
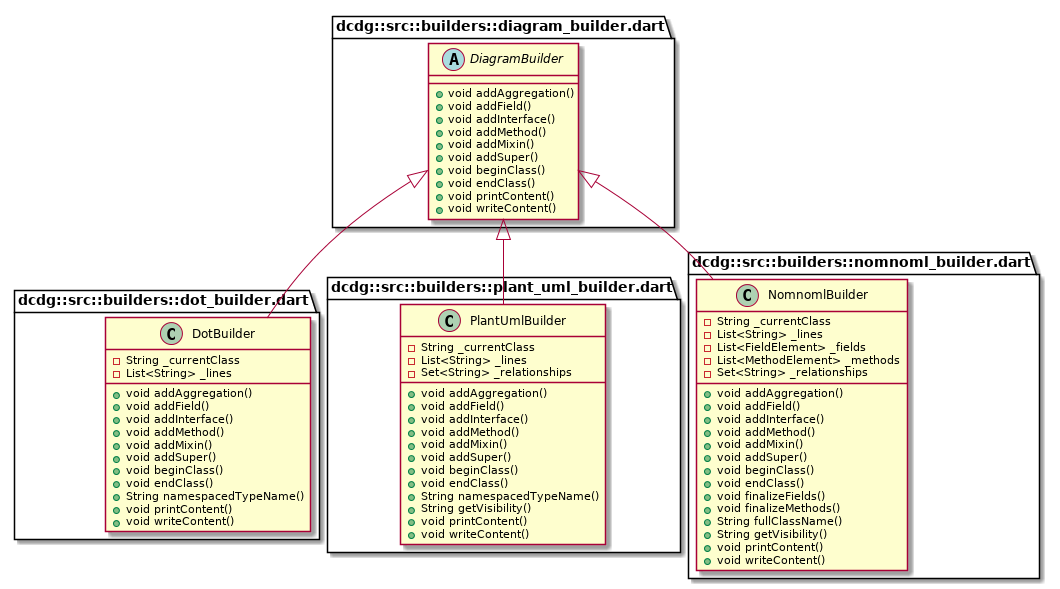
dcdg --is-a DiagramBuilder | plantuml -p > output.pngThere are quite a few other options as well. See dcdg --help for a full list. The source code can be found on GitHub, bug reports and pull requests are welcome.

